
Search engine optimization (SEO) is the method of creating your web content material, so that,…

Google to quit supporting noindex directive within robots.txt
Google formally announced that GoogleBot will no longer follow a Robots.txt directive relevant to indexing. By 1st Sep. 2019, Google will eradicate assisting unsupported and unpublished protocols within the robots exclusive protocol, the corporation declared within the Google Webmaster blog. Which means Google will no longer support robots.txt files with the noindex directive detailed inside the file.
“In the interest of keeping a good ecosystem and preparing for probable future open source releases, we’re retiring all code that handles unsupported and unpublished rules (for example noindex) on September 1, 2019. For those of you who relied on the noindex indexing directive in the robots.txt file, which usually controls crawling, there are a number of other alternatives,” the corporation said.
Robots.txt Noindex Unofficial
The key reason why the noindex robots.txt directive won’t be supported is that it’s certainly not an official directive.
Google has in the past supported this robots.txt directive but this will no longer be the case. Take due notice thereof and also govern on your own consequently.
What’s a “noindex” tag?
Whenever you put in a “noindex” metatag to a webpage, it tells the search engines that even though it may crawl the web page, it cannot add the page into its search index.
Therefore any page with the “noindex” directive onto it will not go into the search engine’s search index, and will therefore possibly not be shown within search engine results pages.
What is actually a “nofollow” tag?
When you add a “nofollow” metatag to a webpage, it disallows search engines from crawling the hyperlinks on that web page. And also this means that any kind of ranking authority the page has upon SERPs won’t be passed on to pages it links to.
So any page with a “nofollow” directive onto it will likely have all its hyperlinks ignored by Search engines
How you can Handle Crawling?
Google’s official article listed five ways to handle indexing:
- Noindex in robots meta tags: Supported both in the HTTP response headers as well as in HTML, the noindex directive is regarded as the efficient way to eliminate URLs from the index when crawling is allowed.
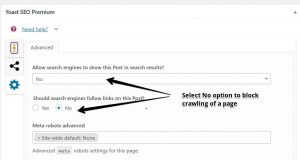
In the WordPress sites you can make use of meta robots tags by the help of Yoast SEO Plugin, just download the plugin and then edit any post or page you would like to noindex or nofollw and come to the bottom of the particular page or post, just select the no option like below screenshot.
- 404 and 410 HTTP status codes: These types of status codes are utilized to notify search engines that a web page no longer exists, which will result in them being dropped from the index, whenever they have been crawled.
- Password protection: Preventing Google from being able to view a page by concealing it behind a login will generally result in it getting removed from the index.
- Search Console Remove URL tool: This URL removal tool within Google Search Console is a fast and simple way to temporarily remove a URL from Google’s search results.
The reason why Google altering now. Google has been looking to change this particular for a long time and with standardizing the protocol, it could possibly now move ahead. Google said it “analyzed the usage of robots.txt rules.” Google focuses on thinking about unsupported implementations of the internet-draft, like crawl-delay, nofollow, as well as noindex. “Since these types of rules weren’t documented by Google, naturally, their usage in relation to Googlebot is very low,” Google said. “These mistakes hurt websites’ existence in Google’s search engine results in ways we don’t think webmasters meant.”
Related Posts


